 Xstreami
Xstreami
- About
- Services
- Blogs
- Careers
- Products
- Contact Schedule a Call




Building reliable real-time MySQL streaming for analytics and AI
This blog explains why MySQL real-time streaming has become essential for modern analytics and AI systems, and how CDC-based architectures enable reliable, observable and scalable data pipelines for fast, data-driven decisions.
Thiyaghu February 06, 2026
Subscribe for email updates

Real-time data is now a business requirement
AI systems, operational dashboards, live alerts, and customer-facing features all have something in common. All of them depend on one thing: fresh data — not data from last night.
Today’s organisations expect answers as events occur:
- Fraud detection should react in milliseconds, not hours.
- A growth dashboard should reflect the last transaction, not yesterday’s batch.
- A recommendation engine should learn from the user’s most recent behaviour.
- Customer apps should reflect real inventory and real status.
In short, real-time data is no longer an engineering luxury.
It is a business capability.
At Mafiree, we’ve seen first-hand how real-time streaming transforms analytics and AI outcomes — driving better dashboards, faster alerts, and more responsive customer systems.
Why batch pipelines cannot support these use cases anymore
Traditional batch pipelines were designed for a different world:
- Nightly ETL jobs
- Delayed reporting
- Offline analytics
- Static dashboards
They work well when latency does not matter. The problem is that modern platforms no longer operate in that comfort zone.
When data arrives late, the impact becomes visible immediately:
- AI feature pipelines train on stale behaviour
- Operational dashboards show an outdated picture of reality
- Alerting systems react after incidents have already escalated
- Customer-facing features display incorrect or old states
When business teams start asking,
“Show me what is happening right now,”
batch processing stops being an optimisation issue and becomes a structural limitation.
The quiet shift: from moving tables to streaming events
A subtle but important change is happening in modern data platforms.
We are no longer just copying tables between systems.
We are streaming changes as events.
Instead of asking:
“What does the table look like now?”
Systems are designed to ask,
“What just changed?”
This is where real-time MySQL streaming and Change Data Capture (CDC) become foundational.

By consuming binary log events directly:
- Inserts become events
- Updates become events
- Deletes become events
This event stream feeds:
- Analytics engines
- AI feature stores
- Search indexes
- Real-time dashboards
- Downstream operational systems
In practice, the database becomes a continuous source of business facts — not just a storage layer.
What “reliable” really means in real-time MySQL streaming
Most teams start streaming quickly. Very few teams get reliability right.
In practice, reliability has nothing to do with raw throughput alone.
It is about correctness under pressure.
A production-grade streaming layer must guarantee:
1. Exactly-once or deterministic processing
Downstream systems must never see duplicated business events.
2. Ordering guarantees per key
Especially important for financial data, inventory, and stateful systems.
3. Schema evolution safety
Columns will be added and types will change, but streaming should not break silently.
4. Recoverability
Restarts, crashes, and network partitions should never corrupt the stream or lose events.
5. Observability
You must know:
- How far the stream is behind
- Where the last committed position is
- How long events take to reach consumers
This is the difference between saying,
“We have a pipeline”
and
“We can trust this pipeline.”
The architecture pattern that works in practice
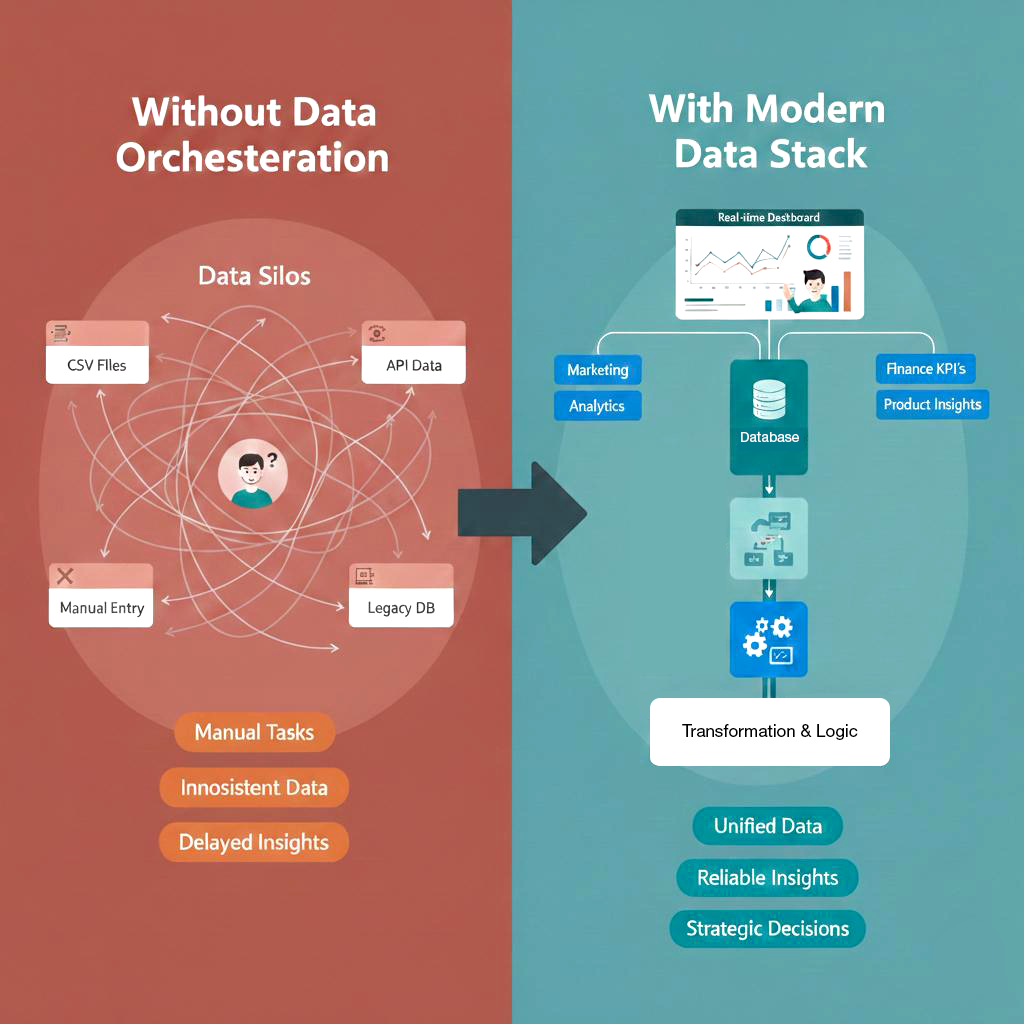
In real deployments, a reliable MySQL streaming architecture usually follows a simple but powerful structure.
- At the source, MySQL runs with binlog enabled and row-based replication.
- A CDC ingestion layer, continuously reads the transaction logs and converts row-level changes into structured events.
- A schema management layer, enforces compatibility rules and protects downstream systems from breaking changes.
- A durable streaming transport, provides reliable delivery and handles back-pressure.
On top of this foundation, multiple independent consumers can operate in parallel, including:
- Analytics platforms,
- AI feature pipelines,
- Alerting services, and
- Product and operational services.
The key design principle is simple:
One source of truth feeding many independent real-time consumers.
This separation allows analytics and AI platforms to evolve independently from operational systems, without coupling release cycles or availability requirements.
For a practical implementation of this architecture using MySQL CDC and robust deliverability, see how Xstreami handles change event streaming and schema management in real production workloads.

Why AI platforms amplify streaming requirements
AI systems are extremely sensitive to data freshness.
Even small delays directly affect:
- Prediction accuracy
- Anomaly detection quality
- Feature drift detection and
- Online learning pipelines.
Across real production environments, a clear shift is now visible.
Training pipelines are no longer purely batch-driven. They are slowly becoming continuous pipelines.
This turns database streaming from a data integration component into a core part of the machine-learning infrastructure itself.
When feature stores are built directly from real-time streams, teams unlock:
- Near-real-time inference
- Faster and safer retraining cycles and
- Consistent feature definitions for both offline training and online serving.
The alignment between operational data and AI pipelines is rapidly becoming a competitive advantage.
Designing for growth, not just for today
The most common mistake in a streaming project is designing only for the first consumer.
A better long-term approach is to assume:
- More downstream systems will join
- New transformation rules will be added
- Regulatory or audit use cases will appear later
- Data products will grow around the stream
That means:
- Schema governance must be built in from day one
- Transformation rules must be versioned
- Replay capability must be supported
- Multi-consumer isolation must be planned
This future-proofs your streaming layer and avoids painful redesigns later.

FAQ
Real-time streaming captures database changes directly from the transaction log and delivers them as events to downstream systems using Change Data Capture (CDC).
Instead of querying tables repeatedly, every insert, update and delete is streamed in near real time to analytics platforms, AI pipelines and operational services.
Traditional ETL pipelines move data in batches and usually introduce minutes or hours of delay.
MySQL CDC streams only the changes from the transaction log, enabling low-latency data delivery, reduced load on the source database and continuous data flow for real-time analytics and AI workloads.
Yes. Real-time MySQL streaming is commonly used to power AI feature pipelines and online feature stores.
By streaming fresh transactional data, models can access up-to-date features, support near-real-time inference and reduce feature drift between training and production.
A production-ready MySQL streaming pipeline must provide deterministic or exactly-once processing, ordered event delivery per key, safe schema evolution, strong recovery guarantees and end-to-end observability across binlog ingestion and consumers.
Yes. A single MySQL CDC stream can safely fan out to multiple consumers such as analytics platforms, AI pipelines, search systems and operational services.
This allows organisations to maintain one source of truth while enabling independent and scalable real-time use cases.
When implemented correctly, MySQL CDC has minimal impact on database performance.
CDC reads changes from the binlog rather than querying tables directly, avoiding heavy read workloads and allowing streaming pipelines to scale without affecting transactional traffic.
Schema changes such as adding columns or modifying data types are common in production.
A reliable streaming setup includes schema management and compatibility checks to ensure downstream systems continue working safely without data loss or silent failures.
Yes. Real-time MySQL streaming is well suited for environments with multiple databases or clusters.
With proper observability and isolation, CDC pipelines can stream data from many sources into shared analytics, AI and operational platforms while maintaining consistency and control.

Leave a Comment
Related Blogs




Subscribe for email updates
Get in touch with us
Highlights
More than 6000 Servers Monitored
Happy Clients
Certified DBAs
24 x 7 x 365 Support

Contacts



Nagercoil Office
Miru IT Park, Vallankumaranvillai,
Nagercoil, Tamilnadu - 629 002.
Bangalore Office
Unit 303, Vanguard Rise,
5th Main, Konena Agrahara,
Old Airport Road, Bangalore - 560 017.
Call: +91 6383016411
Email: sales@mafiree.com