 Xstreami
Xstreami
- About
- Services
- Blogs
- Careers
- Products
- Contact Schedule a Call




What is ETL? How Modern ETL Pipelines Power Real-Time Data
Modern systems don’t suffer from a lack of data — they suffer from too much of it, in too many places. Every service, application, and platform generates its own stream of information. Transactions, logs, user actions, system events — all flowing continuously, but rarely in sync. The real challenge isn’t collecting data anymore. It’s making sense of it. That’s where ETL begins its quiet work in the background.
Shenbaga Varna S May 20, 2026
Subscribe for email updates

The Hidden Chaos Behind Business Data
No one sees it at first.
On the surface, dashboards look clean, reports are structured, and numbers seem reliable. But underneath, data is scattered across systems that were never designed to work together.
A transaction lives in one database.
A user action is logged elsewhere.
Operational signals exist in entirely different formats.
Each system works independently, but together they create fragmentation.
So when a business asks a simple question, the answer becomes complicated — not because the data doesn’t exist, but because it isn’t connected.
This is the hidden chaos: data that is everywhere, yet not immediately usable.
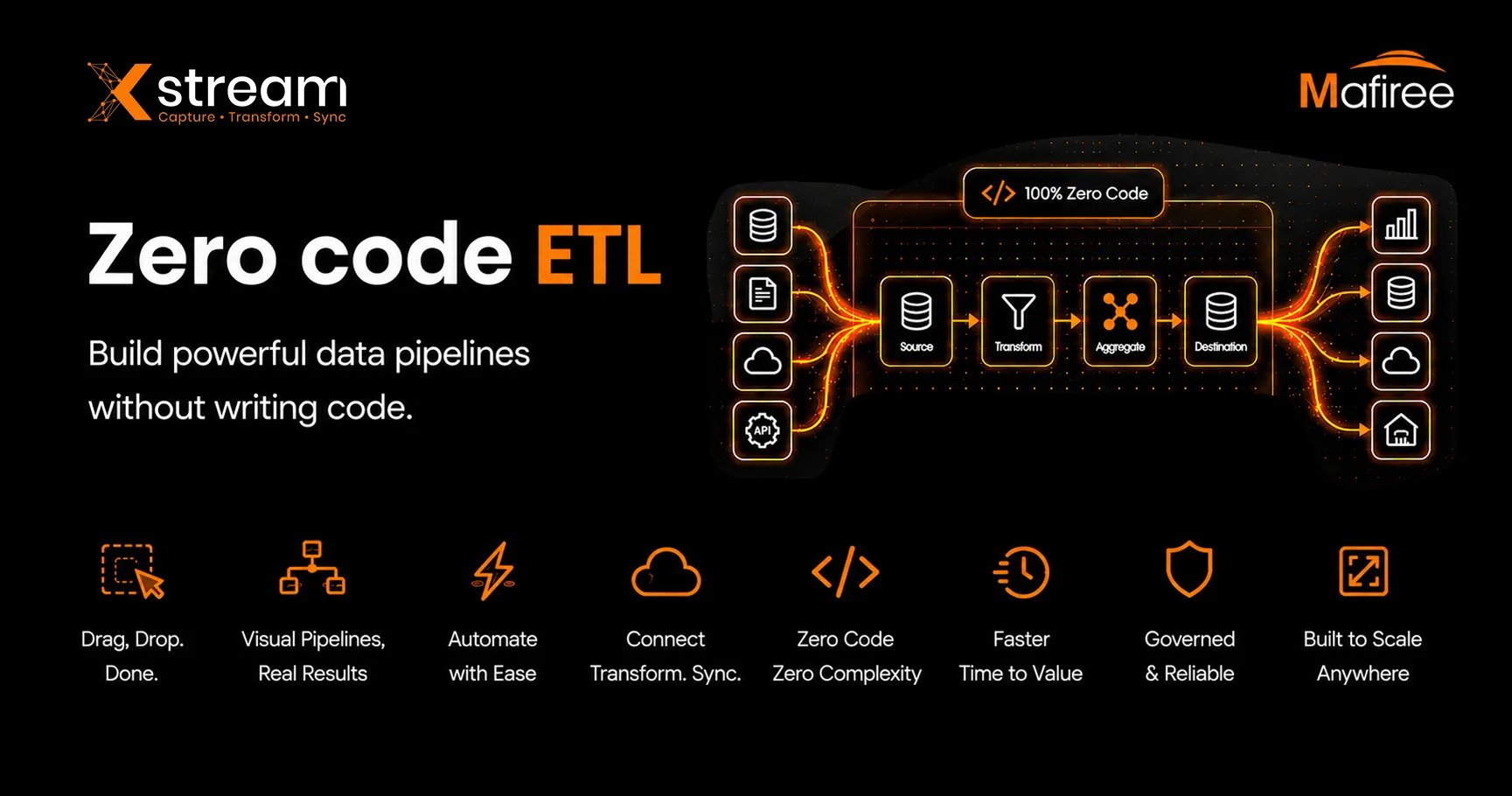
What is ETL?
ETL stands for Extract, Transform, Load. It is a data integration process used to collect data from multiple sources, clean and standardize it, and move it into a destination system such as a data warehouse, analytics platform, or operational environment.
ETL solution for real-time pipelines helps businesses turn disconnected raw data into trusted, usable insights.
The ETL Process in 3 Steps
- Extract – Collect data from databases, applications, APIs, logs, and external systems
- Transform – Clean, validate, standardize, enrich, and restructure data
- Load – Deliver processed data into warehouses, dashboards, lakehouses, or real-time systems
Understanding ETL in Modern Data Systems
Let’s imagine something simple — but very real.
A payment happens on an app.
At the same moment:
- The transaction is stored in a database
- The user’s action is recorded as an event
- A fraud system quietly logs signals in the background —inside the code block
Now here’s the interesting part. All of this data exists.
But it exists in different places, in different formats, and at different speeds.
If someone now asks:
“Is this transaction safe?”
No single system can answer it alone.
The transaction system only knows the payment.
The user system only knows the behavior.
The fraud system only knows patterns.
Individually, they are useful. But together, they tell the full story. This is where ETL comes in.
ETL acts like a smart connector that quietly does three things:
- It collects data from all these systems as it happens
- It cleans and aligns the data so everything makes sense together
- It delivers it to a place where it can be analyzed instantly
So instead of looking at three separate pieces. You now see one complete picture. A transaction is no longer just a record.
It becomes a combination of:
- What happened
- Who did it
- Whether it looks risky
That’s what ETL really does in modern systems. It doesn’t just move data.
It connects pieces of information so systems can think together, not separately.
.webp)
Data Ingestion: The First Step of ETL
In older systems, data was extracted in bulk — large queries, scheduled jobs, periodic pulls.
But modern systems don’t wait. Instead of periodic pulls, data is captured as it occurs.
So when something happens:
- A database update is recorded through change logs using Change Data Capture (CDC).
- An application event is streamed the moment it occurs
- A system action is pushed into a pipeline instantly
Nothing is reprocessed unnecessarily. Only what changes is captured and moved forward. This approach changes everything.
Data ingestion becomes continuous, not periodic. It becomes lightweight, not disruptive. And most importantly, it keeps systems running without interference while still making data available in near real time.
Cleaning, Standardizing, and Enriching Data
Once data starts flowing in, the illusion of completeness disappears.
Because raw data, in its natural state, is unreliable.
- Two systems may store timestamps differently.
- Identifiers may not align.
- Duplicates creep in.
- Critical context is often missing.
Transformation is where discipline is introduced in the Real-Time CDC deployment
- Data is cleaned — removing inconsistencies and errors.
- It is standardized — aligned to common formats and structures.
- And then it is enriched — connected with other datasets to add meaning.
A transaction alone is just a record.
Combined with user data, location, and behavioral patterns… it becomes insight.
This stage doesn’t just improve data — it defines whether it can be trusted at all.
Batch vs Real-Time Data Loading
There was a time when data pipelines moved at a slower pace.
Processing happened in batches — hourly, nightly, sometimes even less frequently. For reporting and historical analysis, this worked well. But modern systems operate in a different reality.
- Decisions are expected instantly.
- Systems react in real time.
- Delays are no longer acceptable.
So data loading has evolved.
Instead of waiting to accumulate, data is pushed forward the moment it’s ready. Dashboards update continuously. Alerts trigger as events occur. Systems respond without pause.
The difference is subtle, but powerful:
- From data that informs later to data that acts immediately.
Change Data Capture in Modern ETL Pipelines
Change Data Capture (CDC) is one of the most important technologies powering real-time ETL.
Rather than re-reading entire databases, CDC captures only inserts, updates, and deletes as they happen.
Benefits of CDC include:
- Lower database load
- Faster synchronization
- Real-time analytics readiness
- Better pipeline efficiency
- Reduced infrastructure costs
CDC is especially valuable for MySQL, PostgreSQL, Oracle, and enterprise transactional systems where speed matters.
.webp)
How ETL Pipelines Work Internally
Behind this seamless flow lies a carefully engineered system.
ETL pipelines are not linear scripts — they are distributed, fault-tolerant architectures designed to handle constant movement.
- Data enters through ingestion layers that capture changes and events.
- It moves through processing engines that apply transformations in parallel.
- Orchestration systems manage dependencies, retries, and execution flow.
- Finally, it is delivered into storage systems optimized for querying and analysis.
At every stage, the system is designed to handle scale, failure, and speed.
Because in modern environments, data doesn’t pause — and neither can the pipeline.
The Shift from Batch to Real-Time ETL
This is where ETL has undergone its most significant transformation. What was once scheduled and predictable is now continuous and dynamic.
Instead of waiting for jobs to run, pipelines respond to events.
Instead of processing large chunks, they handle streams.
This shift points to a deeper transformation in the way businesses function today. Questions are no longer retrospective. They are immediate.
Not “What happened yesterday?”
But “What’s happening right now?”
And ETL has adapted to answer that — in real time.
Real-Time Data Processing Use Cases
This evolution is not theoretical. It’s already shaping critical systems.
- A payment anomaly is detected before a transaction completes.
- A user’s experience adapts in real time based on behavior.
- Operational systems trigger alerts before failures escalate.
These capabilities depend on one thing:
Data that is not just available — but instantly usable. And that is exactly what modern ETL pipelines enable.
.webp)
Common Challenges in ETL Pipelines
As powerful as ETL is, it comes with its own complexity. As systems scale, pipelines must handle:
- Rapidly increasing data volumes
- Constant schema changes
- Strict performance requirements
- The need for high reliability
What begins as a straightforward pipeline can quickly evolve into a system that is difficult to maintain and scale.
Without the right approach, ETL can become:
A bottleneck instead of a bridge.
How Mafiree is Transforming ETL with Xstreami
At Mafiree, this challenge was clear.
Traditional ETL pipelines were not designed for the speed and scale modern systems demand. They required heavy engineering effort, constant maintenance, and often struggled to keep up with real-time needs.
So we built Xstreami.
A platform designed to move beyond rigid pipelines and into continuous data flow.
With Xstreami:
- Data is captured in real time using CDC
- Transformations happen continuously, not in stages
- Data moves seamlessly across systems without delays
The goal was simple:
Remove complexity, and let data flow the way it was always meant to.
The Future of ETL
ETL is no longer just a backend process. It is becoming the foundation of how systems operate. In the future, data pipelines will not be something teams manage manually.
They will be intelligent, adaptive, and always running. Data will not need preparation — it will already be ready. And as systems continue to evolve, one thing becomes clear:
The role of ETL is not shrinking. It is becoming central to everything.
.webp)
Final Thought
Data alone has no value — it becomes useful only when it moves and transforms. ETL makes that possible by turning scattered data into meaningful insight. As systems grow faster, step-by-step processing is no longer enough. With Xstreami, data flows continuously instead of waiting in stages. That’s how real-time decisions are made.
In a world where every second matters, delays in data mean delays in action. Systems that can move and process data instantly are the ones that stay ahead. Continuous data flow is no longer an advantage — it’s becoming the standard.
FAQ
ETL is the process of extracting data from multiple sources, transforming it into a usable format, and loading it into a system for analysis.
It helps turn raw, scattered data into structured and meaningful information.
This makes it easier for systems to generate insights and support decision-making.
Yes (at scale). ETL pipelines can become complex as data volume and system dependencies grow.
They require handling data flow, transformations, and reliability across multiple systems.
Modern tools help simplify this by reducing manual effort and automating pipeline management.
An ETL pipeline works by extracting data, transforming it into a consistent format, and loading it into a target system.
Each stage ensures that the data is clean, structured, and ready for analysis.
This process enables systems to use data efficiently and reliably.
ETL transforms data before loading it into the destination system, while ELT loads data first and transforms it later.
This difference changes where and how processing happens within the pipeline.
The choice between them depends on system architecture and performance needs.
No. ETL is one approach within the broader category of data integration.
It focuses specifically on extracting, transforming, and loading data.
Data integration tools may include ETL as one of their core functionalities
Yes. ETL can connect and combine data from databases, APIs, and applications.
It enables data from different systems to be brought together into a unified view.
This makes cross-system analysis possible and more effective.
Modern ETL pipelines can process data as it is generated instead of waiting for scheduled jobs.
This allows continuous data flow through the system.
As a result, systems can respond faster and make near-real-time decisions.
Yes. ETL reduces load by avoiding repeated full data scans on production systems.
It often works with incremental data movement instead of copying entire datasets.
This helps keep databases stable, efficient, and responsive.
Leave a Comment
Related Blogs




Subscribe for email updates
Get in touch with us
Highlights
More than 6000 Servers Monitored
Happy Clients
Certified DBAs
24 x 7 x 365 Support

Contacts



Nagercoil Office
Miru IT Park, Vallankumaranvillai,
Nagercoil, Tamilnadu - 629 002.
Bangalore Office
Unit 303, Vanguard Rise,
5th Main, Konena Agrahara,
Old Airport Road, Bangalore - 560 017.
Call: +91 6383016411
Email: sales@mafiree.com